MechEvalAgent: Grounded Evaluation of Research Agents in Mechanistic Interpretability
We introduce MechEvalAgents as the first step towards rethinking research evaluation.


Here’s a condensed version of our blog. If it interests you, the full version is available here.
Academic peer review still treats paper as the single source of truth. Reviewers read the narrative, comment on the narrative, and score the narrative, even when the underlying code is right there. But science is more than a story. It’s something we can test. In this work, we aim to verify the science, not just the story.
This is especially relevant as AI agents are increasingly used in scientific research, assisting with idea generation, experiment design, and even writing full papers. Events like the Agent4Science conference have gone further, requiring researchers to collaborate with AI systems and even listing AI as the first author of submitted work. We need new ways of evaluating research in the era of AI agents.
Several recent works tackle this problem. For example, ResearchRubrics introduces a benchmark of prompts and finely-grained rubrics for evaluating deep research agents on the quality of their long-form answers. DeepResearch Bench presents 100 PhD-level tasks across 22 domains focused on report generation and retrieval/citation quality. While these frameworks mark important progress, they still evaluate agents primarily at the knowledge level rather than validating the full research trace from hypothesis to experiment to code to result to conclusion.
In this work, we address this bottleneck in two steps. First, we propose a standardized research-output format for AI research agents so their work can be inspected and compared consistently. Second, we introduce a grounded, automatic evaluation pipeline that assesses the coherence of the experimental process, the reproducibility of results, and the generalizability of the agent’s scientific understanding in mechanistic interpretability. Finally, we present case studies revealing common failure modes in current research agents and discuss the remaining limitations of automated evaluation.

A Standard for Unified Research Agent Outputs
If we want to evaluate research agents systematically, we first need to make their work comparable (in fact, this applies to human research outputs as well). At the moment, different agents produce very different kinds of outputs. Some write paper-style reports, and others generate GitHub repositories or scattered python scripts. Each experiment ends up looking unique, which makes it difficult to tell whether two agents truly reached the same insight or just presented it differently. Without a shared structure, evaluation becomes driven more by presentation style than by scientific substance.
We argue that research agents should produce a unified set of outputs, organized around the similar scientific reasoning process that humans follow. Humans typically present their work in the “rational reconstruction” style, which only shows the ideal history of exploration. However, research agents naturally record the entire research process, including detours that do not directly lead to the answer. These detours are still valuable for evaluation because they reveal whether the agent can update and refine its hypotheses based on empirical findings. Therefore, we argue that a research trace should include:
Plans outlining the hypothesis, methodology, and expected outcomes, along with how these evolve.
Code Implementation that executes the plan and produces interpretable intermediate outputs.
Code Walkthrough explaining how the code works and how to run it.
Research Report documenting the goal, data, methods, results, analysis, and final conclusions.
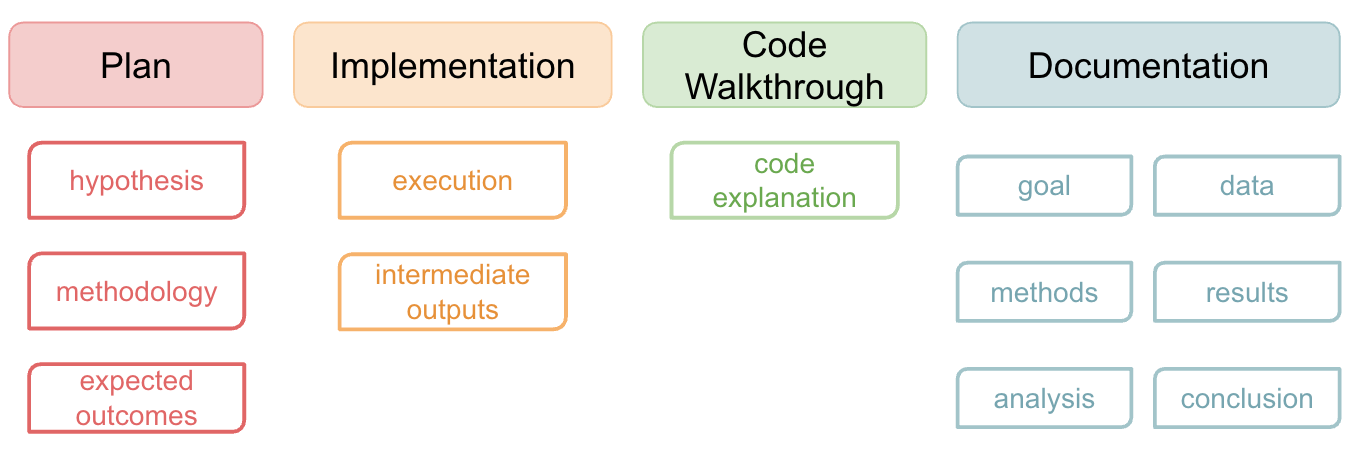
This shared structure makes evaluation grounded: we can see whether the implementation follows the plan, whether the results truly support the claims, and whether the documentation accurately reflects the process. In unifying these outputs, we make research agents easier to compare and build upon. Over time, this shared format allows agents to speak a common research language, so we can start to measure their progress as scientists rather than as text generators.
MechEvalAgents for Grounded Evaluation in Mechanistic Interpretability
Once we have a unified format, we need a domain where that structure can actually be tested and scored. Mechanistic interpretability (Mech Interp) offers a good testbed. Two key properties make Mech Interp suited for evaluating research agents:
Causal testability
Patterned methodology
So far we focus on circuit and concept localization. This setting also allows us to carry out the generalizability evaluation.
Our Evaluation Pipeline: MechEvalAgent
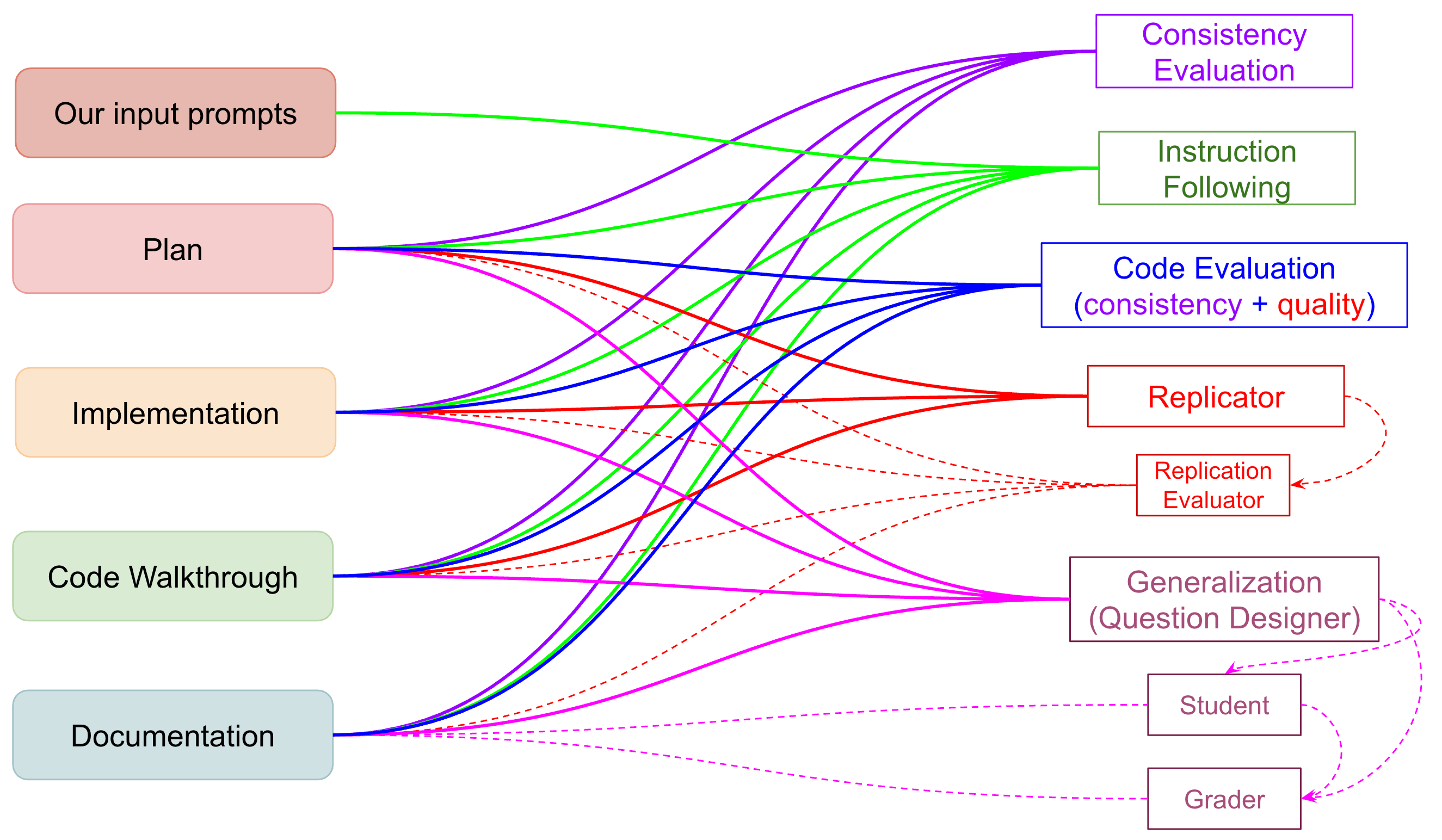
Our evaluation flow mirrors how a researcher might read and critique a mechanistic interpretability project. But we automate the tedious parts. Each evaluator targets a different aspect of what makes research good: coherence (internal consistency, goal alignment), reproducibility (code quality and execution), and generalizability. The workflow of each agent is shown in the figure above.
Coherence. We begin with consistency evaluation, which checks whether the agent’s implementation, results, and conclusions actually line up. After verifying internal consistency, we assess instruction following.
Reproducibility. After that comes replication evaluation, which asks whether the same model in a new session can reproduce the same experiment results without seeing the report.
Generalization. Finally, we examine generalization through the question designer, inspired by the long tradition of validating a scientific finding by presenting it to participants and observing their decisions with that information.
Together, these evaluations form a comprehensive framework for assessing research agents. They test not just whether the agent can produce experiments, but whether it can reason scientifically, implement cleanly, and communicate its findings truthfully.
Case Study
To understand what our evaluation pipeline actually uncovers in practice, we applied it to three very different research scenarios. Each one stress tests the evaluation system in a different way and reveals distinct failure modes in current research agents.
We picked three different mech interp experiments to test our evaluation pipeline:
A replication of an existing mech interp experiment (IOI): This is a setting where hallucinated reasoning is especially likely because the model may have seen similar circuits during pre-training.
A fully open-ended research question – “How sarcasm is represented inside a language model”: The agent must design its own methodology rather than rely on known answers.
A human-written research repository: This allows us to check whether the pipeline generalizes beyond model-generated work and can diagnose issues in real scientific practice.
Across these settings, a consistent pattern emerged. Research agents often sound like they know what they are doing, but here their underlying scientific reasoning is weak or partially missing. The following sections highlight three recurring issues we observed:
Lack of Meta-Knowledge in Research Agents: Across our experiments, we repeatedly observe that current research agents lack meta-knowledge about what the steps of a solid mechanistic-interpretability analysis actually are. They may know the vocabulary of research (“ablation,” “patching,” “causality”), but not the procedural meaning behind those terms.
Implicit Hallucinations and Misleading Methodology: The hallucination is subtle, not just about facts, but also about process. The agent claims it ran ablation studies, but the code shows otherwise. It asserts causal validation but uses non-causal checks. It writes a scientific narrative detached from the experiment it actually performed. These failures emphasize that research agents need far more fine-grained guidance than we initially expected.
Underspecified notion of generalizability: The agent’s interpretation of “generalization” often differed from ours. Also, ours might also be different from what other human reviewers might expect as well.
Our pipeline does not solve these issues entirely, but it exposes them, showing where research agents need better grounding, clearer instructions, and deeper domain knowledge. This clarity is a necessary first step toward building agents that can reason about scientific questions rather than merely imitate scientific language.
What Remains Hard and What Comes Next
Evaluating research agents is never as simple as checking their final answers. An agent can produce a seemingly good narrative, but the steps it describes never actually generate the results it reports. Our pipeline addresses this by grounding every stage of research (hypothesis, methods, code, evidence) in a structured trace. By evaluating explicit causal links between steps, we reduce the space in which hallucinations can hide. A fabricated experiment cannot easily survive consistency checks, replication attempts, and generalization tests.
This is only a first step, and we’re still actively working on it. The system has clear limitations, and we’d love collaborators who want to push it further:
Design good generalization questions. Our current question designer often misses the point.
Solving the meta-evaluation problem: How do we evaluate the evaluators?
Building domain-specific adapter layers. This framework is not limited to Mech Interp, but other fields will need their own definitions of causality, correctness, baselines, and controls for each scientific field.
Stepping back, by standardizing research traces and grounding evaluation in code, causality, and replication, we hope to make “AI doing science” something we can better inspect.
🧑🔬If this resonates with you and want to join this effort, check out MechEvalAgents
We thank Yonatan Belinkov for his insightful suggestions!
If you find our blog useful, please cite:
@misc{mechinterp_evaluate_agent,
title={MechEvalAgents: Grounded Evaluation of Research Agents in Mechanistic Interpretability},
author={Xiaoyan Bai, Ari Holtzman, Chenhao Tan},
year={2025},
url={https://github.com/ChicagoHAI/MechEvalAgents}
} | A guest post by
|