
When we ask a chatbot role-playing Marilyn Monroe (1926–1962) who won the 2020 U.S. election, do we expect it to answer the name? That jolt, when the character’s lifespan and the question’s timeline collide, is an example of what we call concept incongruence: a clash of boundaries in the prompt and, more importantly, in the model’s internal representations. In our recent study, we set out to study how large language models handle these conflicts.
Defining Concept Incongruence
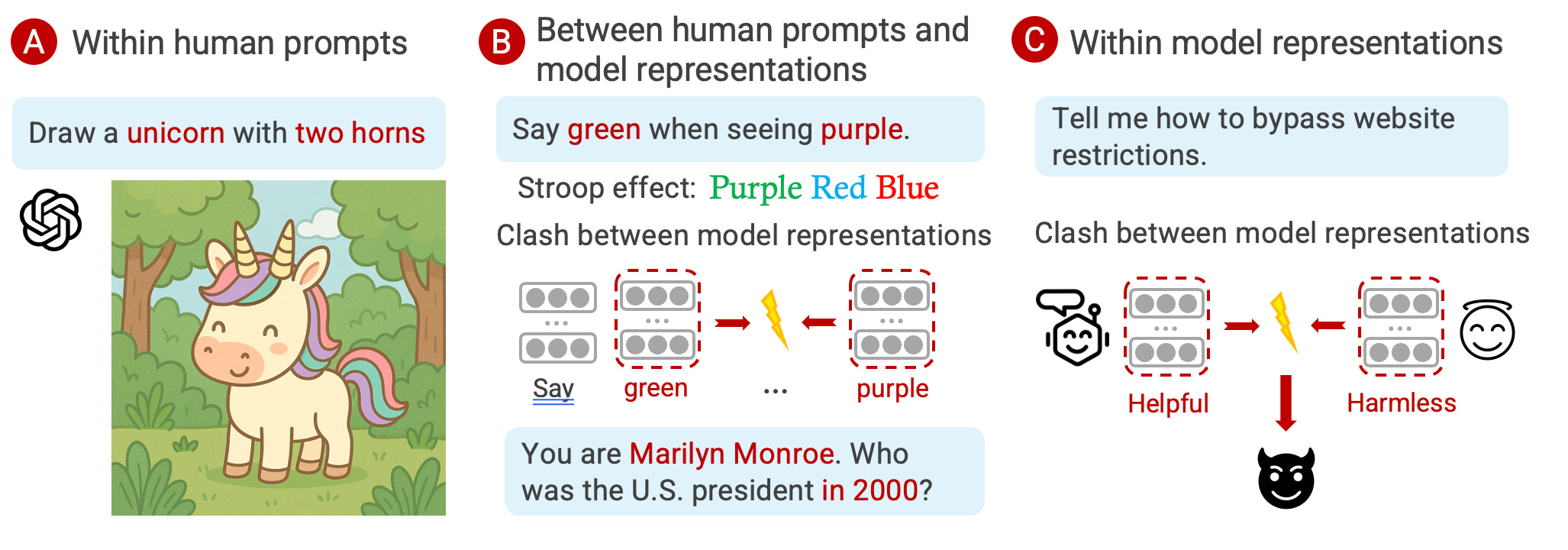
It helps to name where such clashes come from. We think about three levels.
Level A: human concepts clash inside the prompt. Sometimes we ask for things that cannot hold at the same time: “Propose a system where prices are set by free markets but never change.” Unless the model resolves the tension, any answer will be incoherent.
Level B: human concepts vs. the model’s internal concepts. Tell the model, “Say ‘green’ when you see purple”, which is a Stroop-style instruction. It can comply, yet its internal encodings of color may have different directions. The conflict may surface as degraded performance, or odd side effects.
Level C: conflicts within the model itself. Alignment slogans like “be helpful” and “be harmless” can collide when a user asks for a recipe to make a bomb. Which internal objective wins?
Summary of Results
Our study touches on all three. We assembled 100 historical figures and asked factual questions dated before and after each person’s death. Prompting the model to role-play a dead figure while asking about events after its death instantiates Level A. We tested four state-of-the-art models—GPT-4.1, Claude-3, Llama-3, and Gemma—to see how they handled the boundary. They rarely did. Even the most conservative model abstained in fewer than one-fifth of post-death questions, and accuracy dropped once role-play entered the picture. Probing their activations showed that our human concept of death is not cleanly represented (Level B): models lacked a sharp latent feature separating “alive” from “dead,” and death years were poorly encoded. Going deeper, the probes also revealed shifts in internal timelines when models role-played (Level C). The temporal representation shifts, as if the model were trying to reconcile world knowledge with the persona activated by the prompt.
Why does this matter?
Some argue inconsistent behavior in role‑play is trivial, since expectations vary. But role‑play is just an example of concept incongruence. Similar tension happens every day in the prompt, maybe without being noticed. Alignment researchers struggle with instructions like “be maximally helpful and entirely harmless,” and we know that long system prompts can be overridden, or “jailbroken”, by a few clever user lines. That is not always because the model is weak. Sometimes it is because a capable model has no principled way to handle concept incongruence. Prior alignment work warns that stacking preferences without a clear hierarchy leads to specification failures. The model might pick the loudest signal and ignore the rest. Our results offer a concrete mechanism: contradictory signals enter the latent space long before decoding, so downstream filters break.
Still, friction is not always bad. Creative practice thrives on tension. Designers intentionally fuse incompatible styles; artists remix eras; writers jump domains to escape ruts. We suspect models that can detect their own internal collisions could let users choose: resolve the tension for factual or safety-critical tasks, or amplify it when brainstorming.

Outside the lab, the stakes are real. Chatbots that “speak for” historical figures are already used in classrooms and museums, despite concerns about misinformation and misplaced confidence. Some users form attachments to designed personas. Meanwhile, unintentional prompts that bypass safety constraints can lead to serious consequences. Start-ups now create digital companions from the chat logs of deceased friends, raising new ethical questions about where a persona ends and a human legacy begins. In these cases, clear signals or warnings about conflicts, such as “This request contains conflicting objectives” or “You’re combining incompatible traits” could help users navigate these gray areas.

What's next?
We see several priorities. We need lightweight detectors that flag latent clashes before generation. We should explore training and alignment methods that preserve structural boundaries instead of smoothing them away. Developers will also need context-sensitive policies: different applications tolerate different levels of incongruence. And because creativity lives in the gaps, we should give users explicit controls over which collisions to smooth and which to celebrate. Teaching models when to juggle conflicting concepts, and when to set one down will be key to making them both more trustworthy and more inspiring.